有了上次使用模板爬取数据的经验,相信大家应该能够更加熟练的使用Octopus Collector了。也许有的朋友好奇,我们只能通过软件预设的模板来爬取数据吗?当然不是。 Octopus Collector还具有自定义采集功能,供用户采集自己想要的数据。与预设模块相比,定制更加灵活。虽然比预设的模板要复杂一些,但爬虫获取到的数据也会更符合你的意愿。本文小编将为大家带来八达通采集器自定义模块的教程。
步骤1 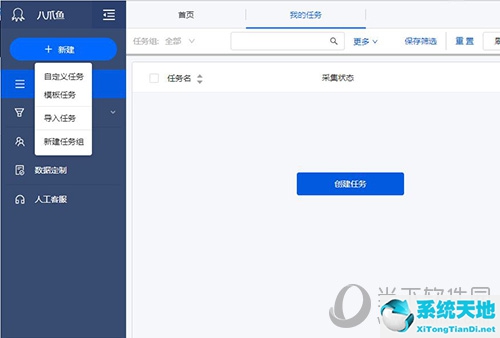
首先,像往常一样,启动并登录您的Octopus Collector,进入主界面,点击【新建】下的【新建任务组】来创建一个新组。
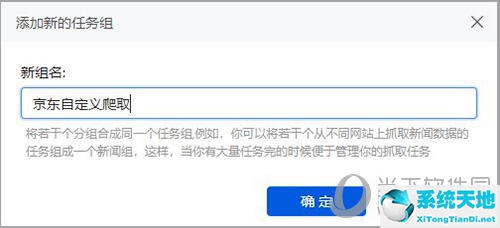
单击“确定”创建新组
步骤2 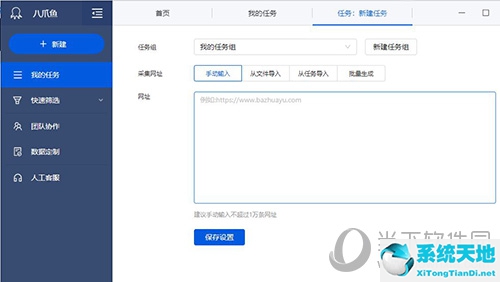
创建组后,点击【新建】下的自定义任务,你会看到这样的界面。
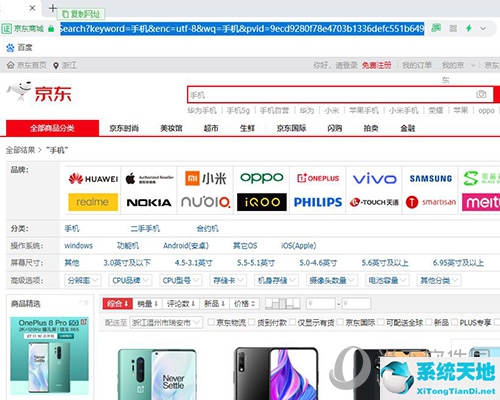
我们可以寻找我们想要抓取的网页的链接。这里,小编就去京东搜索手机。当搜索结果出来后,我们可以复制链接。
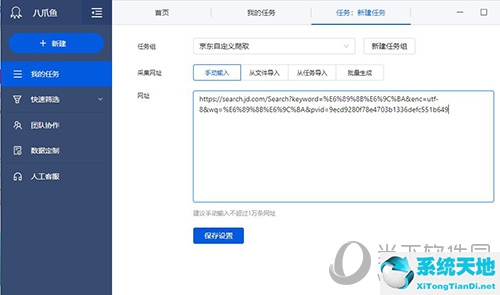
将我们复制的链接粘贴到URL栏中,将任务组更改为之前创建的组,然后单击【保存设置】。
步骤3 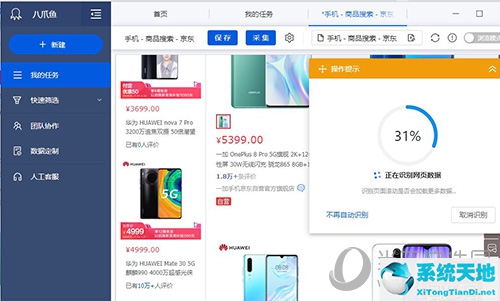
保存设置后,会跳转到抓取界面,软件会自动开始识别要抓取的网页部分。根据每台机器网络速度的不同,相应的等待时间也会有所不同。
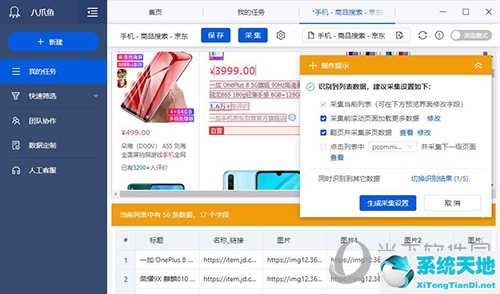
识别完成后,我们可以看到有很多数据,其中有很多无用的数据需要我们剔除。
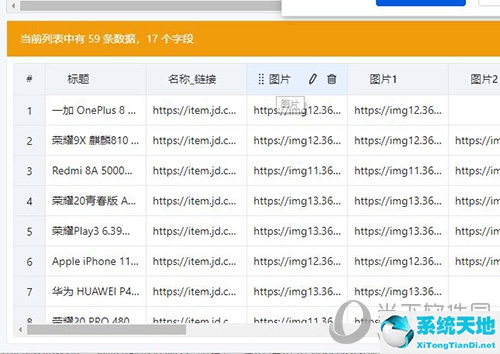
将光标移动到表格字段,将出现两个图标。钢笔图标是更改字段名称,垃圾桶是删除字段。
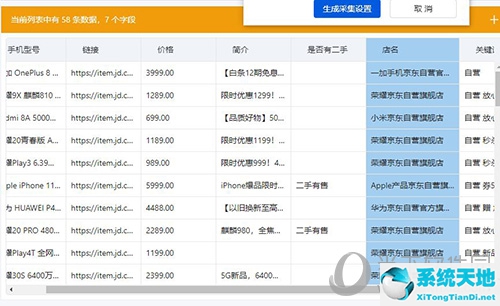
我们可以自由删除和更改字段名称。这里我只保留上图中的字段。
步骤4 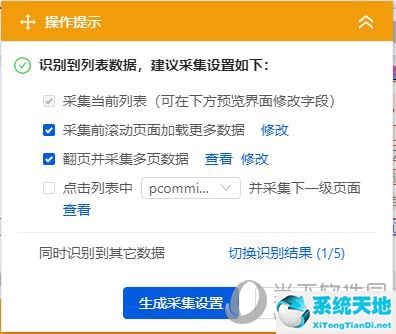
设置完字段后,我们将注意力转向上图中的小方框。第一个是不可选的,所以我们直接忽略它。
采集前滚动页面加载更多数据:由于现在很多网站都使用动态页面,加载时有些内容不会显示。只有当我们下拉的时候才会逐渐显示出来。这个功能就是为了防止这种情况发生。
翻页并采集多页数据:设置抓取多个页面,取消勾选仅抓取当前页面。
点击列表中的XXX,采集下一级页面:该功能可以让我们抓取子页面内的内容。
这里我们不深入爬取,只勾选前两项,然后点击【生成集合设置】。
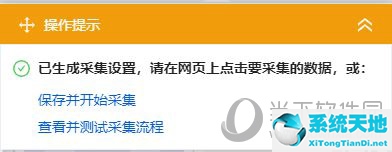
单击“生成”后,系统将要求您开始保存或查看。单击此处保存并开始收集。
步骤5 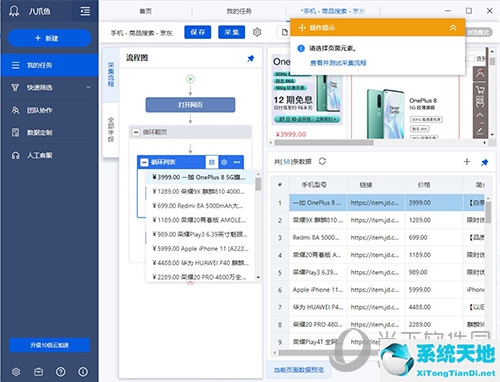
到达这个界面后,我们可以看到一个详细的流程。内循环列表就是本页面爬取的内容。
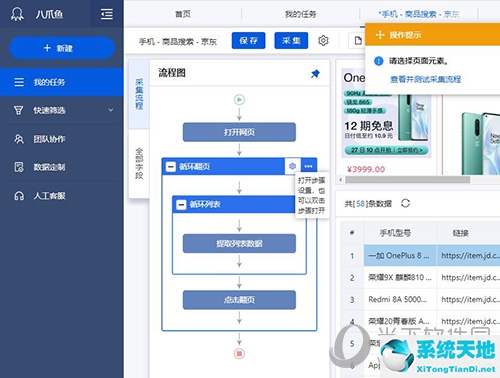
我们点击外循环的设置按钮。
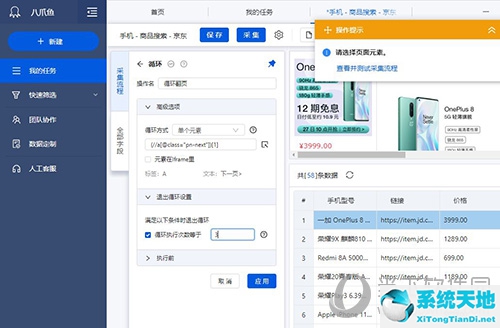
展开退出循环设置并检查循环执行次数。这里我们只爬取3页。
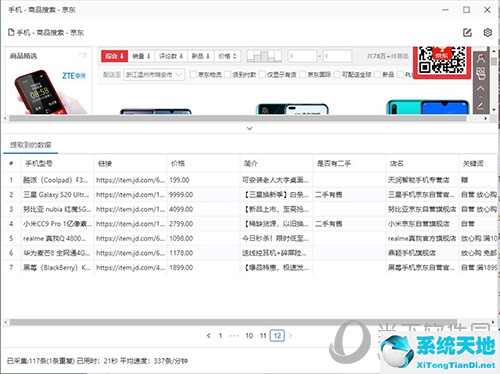
开始收集
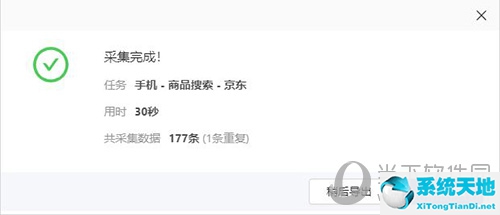
采集完成后,点击导出。
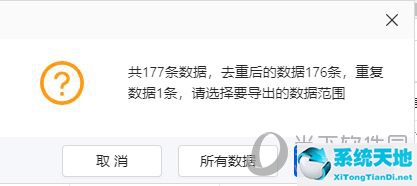
另外,如果你抓取的页面中存在重复数据,软件也会直接提示你根据自己的情况选择保留还是删除。
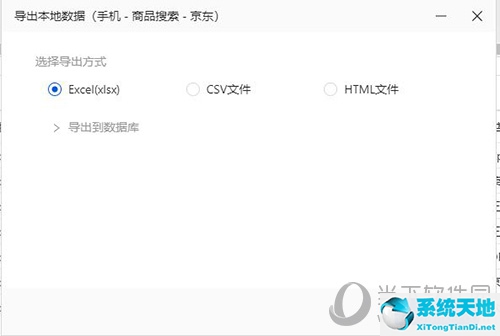
导出方式
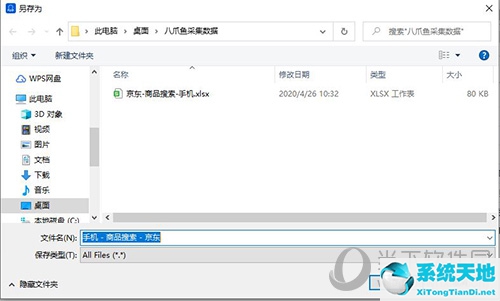
导出的文件保存在哪里
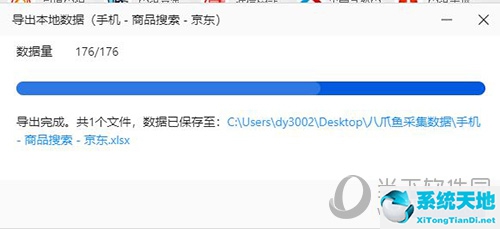
保存完成
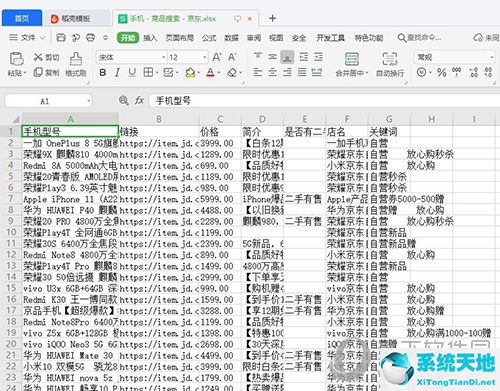
查看数据
以上就是小编为大家带来的Octopus Collector自定义模块教程。熟练使用后,相信小伙伴们可以收集到更多的数据。使用八达通采集器采集数据后,您可以根据采集到的数据使用八达通采集器进行数据采集。进行分析并完成各项任务。希望这篇文章能够对大家有所帮助。